
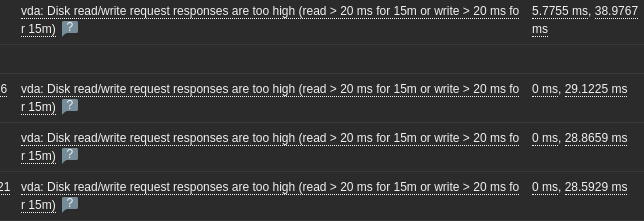
今天很高兴的开启我的k8s集群,准备上号学习。结果监控系统出现大量集群磁盘饱和度告警。于是立马排查。告警截图如下
我们知道在linux中有个命令是排查磁盘的叫-> iostat,如果没有此命令的可以执行-> yum install -y sysstat,话不多说,开始排查。
我在系统中执行iostat,出现如下返回。截图如下

我说下这命令的看法.
avg-cpu: 这一行是和cpu相关
rrqm/s:每秒读请求被合并次数
wrqm/s:每秒写请求被合并次数
r/s:每秒完成的读次数
w/s:每秒完成的写次数
rkB/s:每秒读数据量(kb)
wkB/s:每秒写数据量(kb)
avgrq-sz:平均每次IO请求的扇区大小
avgqu-sz:平均每次IO请求的队列长度(越短越好)
await:平均每次IO请求等待时间(毫秒),通常的系统IO等待时间应该低于5ms,若是大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,通常状况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
r_await:读的平均耗时(毫秒)
w_await:写入平均耗时(毫秒)
svctm:平均每次IO请求处理时间(毫秒),若是svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,若是await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
%util:IO队列非空比例,该参数暗示了设备的繁忙程度。若是该参数是100%表示设备已经接近满负荷运行了
可以看见我的await是45.85毫秒,而svctm是25.7毫秒,io平均等待时间远超io平均处理时间。这说明系统负载有点大。而且我的写入平均耗时,长时间在40多毫秒以上,这已是监控系统告警的原因,此时可以用linux中的宁外的一个命令来查看那个进程占用了大量的io -> iotop ,在终端执行iotop,我的执行结果如下

可以看见是etcd数据库占用了大部分io,我尝试重启etcd数据库,然而并没有解决io情况,后面查看后,应该是我物理机磁盘性能不太行导致的,因为本人用的是hdd很老那种,是从笔记本上拆下来安装到服务器上的。后期在换ssd吧!